
📺 screenpipe #13 | how we built UI traversal & local-first audio transcription
screenpipe #013
⬇️ download mac m app
⬇️ download windows app
give us a ⭐️(11.5k) to help the algorithm
hey louis & matt here
this week we've been focusing on the underlying data quality, as we call it the AI-ready lifetime digital archive. we will share some deeper technical details here, but next newsletter will be a regular one!
as you can imagine building a prototype takes only a few hours while building a scalable product that can be reliably installed and work 24/7 cross-platform across different hardware architectures is a different story
let's dive deeper into how we are changing our core data sources:
🎙️ local first audio transcription
the whole pipeline now looks like this:
first, based on your device, extract segments of speakers through voice embeddings that we store locally in a vector database so screenpipe knows everyone you spoke to
then we run a series of audio processing such as converting multi-channel audio to mono using weighted averaging, resampling to 16khz for whisper compatibility, normalize audio using RMS and peak normalization, spectral subtraction for noise reduction, use realfft for efficient fourier transforms
after the audio processing we classify audio frames between speech and silence using a voice activity detection model powered by onnx, if there is enough speech for a certain period of time, followed by a silence, we transcribe the audio
we use sliding window analysis for a more robust speech detection, then we remove overlapping words, and frame history for better context awareness
the raw audio data is then encoded into mp4 using efficient h265 encoding to files on your disk, saved to database, and made accessible to our API
we are experimenting with post-processing your transcription to augment it with broader context using llama3.2-1b for example which only uses 1 GB of memory, but this is not trivial yet to have enough upsides without increasing too much the resource usage
🧑🏻💻 screen text data - the art of capturing dynamic UI
imagine trying to read a book where the pages constantly shuffle and rearrange themselves while text is mixed with duplicated titles and page numbers in random order. that's essentially what we face when capturing ui content from modern applications. let me share our journey of solving this digital puzzle.
the challenge
modern apps are like living organisms - buttons appear and disappear, text fields update in real-time, and windows transform based on user interactions. our mission? to create a reliable record of this ever-changing landscape.
our approach & hurdles
the depth dilemma
we start by diving into the ui hierarchy, but some apps are like endless mazes. we discovered windows with over 1,000 child elements! to prevent getting lost, we implemented a depth limit of 100 levels - deep enough to capture meaningful content, shallow enough to avoid infinite loops. there is also a lower level deep dive to how exactly we create key for unique elements, and how we map that in UI hierarchy considering that some UI links actually create a circle resulting in infinite traversal loops.
the duplicate detective
as we traverse the ui, we often encounter the same text multiple times. a simple "save" button might appear in the hierarchy through different paths. we built a smart deduplication system which tracks seen text while preserving context, ensuring each unique piece of information appears only once.
memory vs completeness
some applications generate massive amounts of text - we've seen cases exceeding 1 million characters! to keep things manageable while preserving history, we implemented a rolling buffer of 300,000 characters, prioritizing newer content while maintaining enough history for context.
the race against time
ui changes can trigger multiple notifications in rapid succession. rather than processing each one immediately, we implemented a 200ms debounce timer that collects and batches changes. this not only improves performance but also ensures we capture related changes together.
the result
the final text output emerges as a carefully curated stream of consciousness - indented to maintain hierarchy, deduplicated to avoid noise, and timestamped to maintain history. it's like creating a living document that breathes with the application, capturing its essence while filtering out the chaos.
when new content arrives, we don't just append it - we carefully weave it into the existing narrative, checking if it's truly novel or just a variation of something we've seen before. this creates a coherent story of the ui's evolution rather than a simple log of changes.
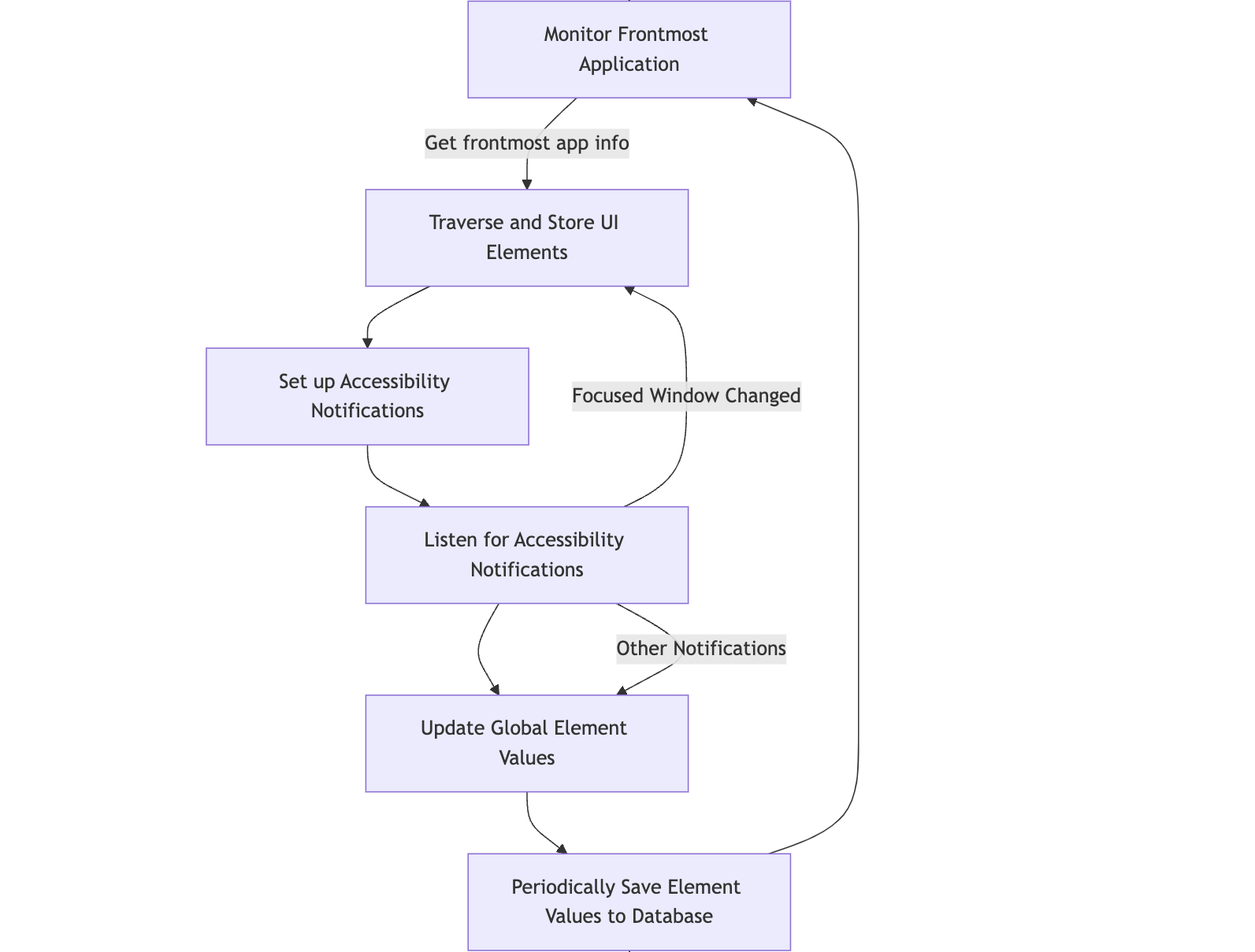
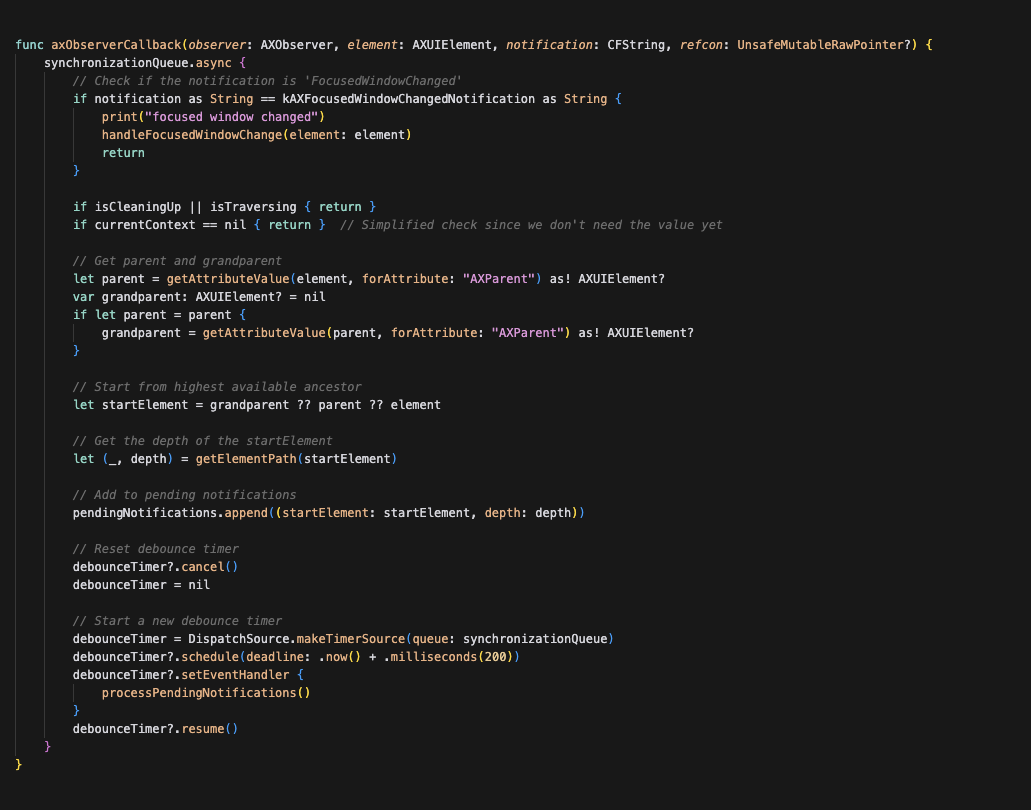
the part that took the most time turned out to be handling notifications for UI changes.
this is complex because we need to handle rapid-fire UI updates without missing changes while also preventing duplicate processing. we also traverse up the hierarchy to find the highest changed element. but the worst part was the fact that a notification of an element doesn't mean that this element changed, the actual change might have happened in a different UI branch which you need to identify without running a computationally intensive re-traversal, take a look:
🤔 what's next:
- extract memories from your screen and audio data, things like your personal data, projects you work on, your tasks, your hobbies, your friends, anything that will help LLM generate higher quality responses to your queries, and will also help you draft e-mails, text messages, help you pre-fill repetitive online forms
- live transcription feature, stream transcription of any meeting to any app, and also get real time advice from LLM powered with historical context about you
btw, we keep growing, thank you for your support
🙏 ask
hey, your feedback and support are super valuable to us, hit the reply button and tell us what you'd like to see in screenpipe.
like screenpipe? mention it online, it would help us grow! 🚀
you can tag screenpipe on x and we will retweet you ❤️
- the app is still in alpha and we've fixed tons of bugs, however, we're releasing daily updates to fix them, along with new features. we're a two-person team, but we have open source contributors, and we would be happy to welcome more of them! ☺️🙏
links
take care,
screenpipe
wanna chat?
You are receiving this email because you opted-in to receive updates from Screenpipe
Screenpipe, 2 Marina Blvd B300, San Francisco, CA 94123